Lab 4 — Broadcast and Gossip algorithms
Question 1 — Broadcast et Workers concurrents
package main
import "fmt"
func main() {
jobs := make(chan int, 5)
done_1 := make(chan bool)
done_2 := make(chan bool)
go func() {
for {
j, more := <-jobs
if more {
fmt.Println("1 received job", j)
} else {
fmt.Println("1 received all jobs")
done_1 <- true
return
}
}
}()
go func() {
for {
j, more := <-jobs
if more {
fmt.Println("2 received job", j)
} else {
fmt.Println("2 received all jobs")
done_2 <- true
return
}
}
}()
for j := 1; j <= 3; j++ {
jobs <- j
fmt.Println("sent job", j)
}
close(jobs)
fmt.Println("sent all jobs")
<-done_1
<-done_2
}Trois goroutines tournent en même temps : la goroutine principale et les deux workers.
Ci-dessous, on observer l'architecture des goroutines.
Main
Worker 1
Worker 2
Les jobs sont répartis entre les deux workers. Un job ne peut être consommé qu'une seule fois. Chaque worker prend ce qu'il lit en premier, donc ils se partagent le flux.
Sur ce backend Google Cloud exécuté dans un container Docker, on observe que le résultat est quasi déterministe : la goroutine 2 reçoit presque tous les jobs avant la 1. Après m'être renseigné, cela s'expliquerai par le scheduler Go combiné à la configuration du container (nombre de vCPUs limité, isolation du Docker), ce qui réduit la concurrence et l'aléa dans l'ordonnancement des goroutines par rapport à un PC local.
Question 2 — Architectures Alternatives
Pour que les deux workers reçoivent tous les jobs, on ajoute d'abord une routine de broadcast. Cette routine lit les jobs depuis le canal principal et les distribue immédiatement à chaque worker au fur et à mesure qu'elle les reçoit.
Main
Worker 1
Worker 2
All Done 1
All Done 2
package main
import "fmt"
func main() {
jobs := make(chan int)
done_1 := make(chan bool)
done_2 := make(chan bool)
// Canaux pour chaque worker
worker1 := make(chan int)
worker2 := make(chan int)
// Broadcast routine
go func() {
for j := range jobs {
// envoyer à chaque worker
worker1 <- j
worker2 <- j
}
close(worker1)
close(worker2)
}()
// Worker 1
go func() {
for j := range worker1 {
fmt.Println("1 received job", j)
}
fmt.Println("1 received all jobs")
done_1 <- true
}()
// Worker 2
go func() {
for j := range worker2 {
fmt.Println("2 received job", j)
}
fmt.Println("2 received all jobs")
done_2 <- true
}()
// Envoyer les jobs dans le canal broadcast
for j := 1; j <= 3; j++ {
jobs <- j
fmt.Println("sent job", j)
}
close(jobs)
fmt.Println("sent all jobs")
<-done_1
<-done_2
}Chaque job est dupliqué et envoyé dans les canaux spécifiques à chaque worker. Ainsi, chaque worker voit tous les jobs et aucun n'est perdu.
Main
Worker 1
Worker 2
All Done 1
All Done 2
package main
import "fmt"
func main() {
jobs1 := make(chan int, 3)
jobs2 := make(chan int, 3)
done_1 := make(chan bool)
done_2 := make(chan bool)
// Worker 1
go func() {
for j := range jobs1 {
fmt.Println("1 received job", j)
}
fmt.Println("1 received all jobs")
done_1 <- true
}()
// Worker 2
go func() {
for j := range jobs2 {
fmt.Println("2 received job", j)
}
fmt.Println("2 received all jobs")
done_2 <- true
}()
// Envoyer les jobs séparément
for j := 1; j <= 3; j++ {
jobs1 <- j
jobs2 <- j
fmt.Println("sent job", j, "to both channels")
}
close(jobs1)
close(jobs2)
fmt.Println("sent all jobs")
<-done_1
<-done_2
}Question 3 — Failure Detection
On a deux routines : la goroutine principale qui envoie des jobs au worker (Node1). Ils sont symbolisés ici par deux noeuds. Pour implémenter le failure detector, on ajoute deux channels supplémentaires entre les deux noeuds pour les heartbeats et les réponses. Ces channels sont symbolisés par des edges entre nos deux noeuds. Periodiquement, le noeud principal envoie une requête de heartbeat au worker, il y répond alors avec un délai de plus en plus élevé pour simuler un ralentissement progressif. Si la réponse n'est pas reçue dans le délai imparti (configurable ci-dessous), le worker est considéré comme défaillant et la routine principale arrête d'envoyer des jobs.
Le délai d'attente pour la réponse du heartbeat peut être ajusté ci-dessous :
secondes
package main
import (
"fmt"
"time"
)
func main() {
jobs_1 := make(chan int, 5)
heartbeat := make(chan int) // channel for heartbeat requests
heartbeatReply := make(chan int) // channel for heartbeat replies
done := make(chan bool)
// Worker goroutine
go func() {
i := 1
for {
select {
case j, more := <-jobs_1:
if more {
fmt.Println("Node 1 received job", j)
} else {
fmt.Println("Node 1 received all jobs")
done <- true
return
}
case hb, more := <-heartbeat:
if more {
fmt.Println("Node 1 received the heartbeat", hb)
// simulate slow-down / failure
time.Sleep(time.Duration(i) * time.Second)
i++
// reply to main
heartbeatReply <- hb
} else {
fmt.Println("I'm not receiving jobs")
done <- true
return
}
}
}
}()
// MAIN GOROUTINE
for j := 1; j <= 10; j++ {
if j%2 == 1 {
// Normal job
jobs_1 <- j
fmt.Println("sent job", j)
} else {
// HEARTBEAT REQUEST
fmt.Println("sent heartbeat", j)
heartbeat <- j
// FAILURE DETECTOR
select {
case <-heartbeatReply:
fmt.Println("received heartbeat reply", j)
case <-time.After(2 * time.Second):
fmt.Println("FAILURE DETECTED: worker too slow")
close(jobs_1)
close(heartbeat)
close(heartbeatReply)
return
}
}
}
close(jobs_1)
fmt.Println("sent all jobs")
<-done
}Question 4 — Cas n noeuds
Pour que node i puisse communiquer vers node j, il faut un canal de jobs un canal de heartbeat et un canal de heartbeat reply. La communication devant être asymétrique, il nous faut dupliquer tout cela. Il nous faut donc 2 canaux de jobs, 2 canaux de heartbeat et 2 canaux de heartbeat reply pour que les deux nodes puissent communiquer entre eux. Chaque node aura une goroutine qui écoutera les jobs et les heartbeats entrants, et une autre goroutine dans la routine principale qui enverra les jobs et les heartbeats. Le failure detector sera également implémenté dans la routine principale pour chaque node, surveillant les réponses aux heartbeats. Ainsi, chaque node pourra envoyer et recevoir des jobs et des heartbeats de manière indépendante, tout en détectant les défaillances de l'autre node.
type Communications struct {
Jobs_ij chan int
Jobs_ji chan int
Heartbeat_ij chan int
Heartbeat_ji chan int
HeartbeatReply_ij chan int
HeartbeatReply_ji chan int
}Question 5 — sending_job et handling_jobs
func sending_job(id int, interarrival_time int, Jobs_Sent chan int) {
jobID := 1
for {
Jobs_Sent <- jobID
fmt.Printf("node %d → sent job %d\n", id, jobID)
jobID++
time.Sleep(time.Duration(interarrival_time) * time.Second)
}
}
func handling_jobs(id int, Jobs_Received chan int) {
for job := range Jobs_Received {
fmt.Printf("node %d → received job %d (discarded)\n", id, job)
}
}Question 6 — Heartbeat
func answering_heartbeat(id int, Heartbeat_Received chan int, ACK_Sent chan int) {
for {
hb, ok := <-Heartbeat_Received
if !ok {
// le canal est fermé, on arrête la goroutine
return
}
// petite sieste proportionnelle à l’ID du node
time.Sleep(time.Duration(id) * time.Second)
// Réponse
ACK_Sent <- hb
fmt.Printf("node %d → ACK heartbeat %d\n", id, hb)
}
}Question 7 — Failure Detection
Le failure detector envoie un heartbeat et attend l’ACK. Le
case <-time.After(100) sert de limite : si aucun ACK n’arrive avant l’expiration, on considère que le voisin est trop lent ou en faute. À chaque réponse, ou absence de réponse, le node mesure le temps, met à jour sa moyenne, puis envoie le heartbeat suivant.Après avoir fait la suite, j'ai réalisé que l'unité de temps n'était pas cohérente avec le reste du code. J'ai donc modifié le code pour que les temps soient en secondes, comme dans les autres fonctions. Le temps de timeout est réglable en fin de question 9.
func failure_detector(id int, Heartbeat_Sent chan int, ACK_Received chan int) {
var j int = 1
var estimate_time float64 = 1
var average_response_time float64 = 1
var i float64 = 1
// premier heartbeat envoyé
start := time.Now()
Heartbeat_Sent <- j
for {
select {
case <-time.After(2 * time.Second):
// timeout -> pas d'ACK à temps
elapsed := float64(time.Since(start).Milliseconds())
estimate_time = elapsed
fmt.Printf("node %d → timeout on heartbeat %d (est %.1f ms, avg %.1f ms)\n",
id, j, estimate_time, average_response_time)
return
case ack, ok := <-ACK_Received:
if !ok {
// le canal est fermé, on arrête la goroutine
return
}
// Vérifier que l'ACK correspond bien au heartbeat courant.
if ack != j {
fmt.Printf("node %d → received stale ACK %d (expect %d), ignoring\n", id, ack, j)
continue
}
// ACK reçu -> réponse OK
elapsed := float64(time.Since(start).Seconds())
estimate_time = elapsed
// mise à jour moyenne
average_response_time = (average_response_time*i + estimate_time) / (i + 1)
i++
fmt.Printf("node %d → ACK heartbeat %d (resp %.1f s, avg %.1f s)\n",
id, j, estimate_time, average_response_time)
// heartbeat suivant
j++
start = time.Now()
Heartbeat_Sent <- j
}
}
}Question 8 — Analyse
Le code construit un petit réseau où chaque paire de nodes communique via un ensemble complet de canaux : jobs, heartbeats et ACKs, dans les deux directions. Pour chaque relation (i → j), une structure Communications est créée avec tous les canaux nécessaires, puis deux routines Node sont lancées : une pour i vers j, et une pour j vers i. Chaque Node active quatre modules : l’envoi de jobs, la gestion des jobs reçus, le failure detector pour suivre les temps de réponse, et la réponse aux heartbeats entrants. Comme un node peut parler à plusieurs voisins, ces modules sont instanciés une fois par voisin. La topologie utilisée correspond à une boucle entre trois nodes : 1 → 2, 2 → 3, 3 → 1. Chaque lien possède ses canaux propres dans les deux sens, formant un anneau où chaque node observe son suivant et lui envoie jobs et heartbeats en continu.
Topologie utilisée dans le code
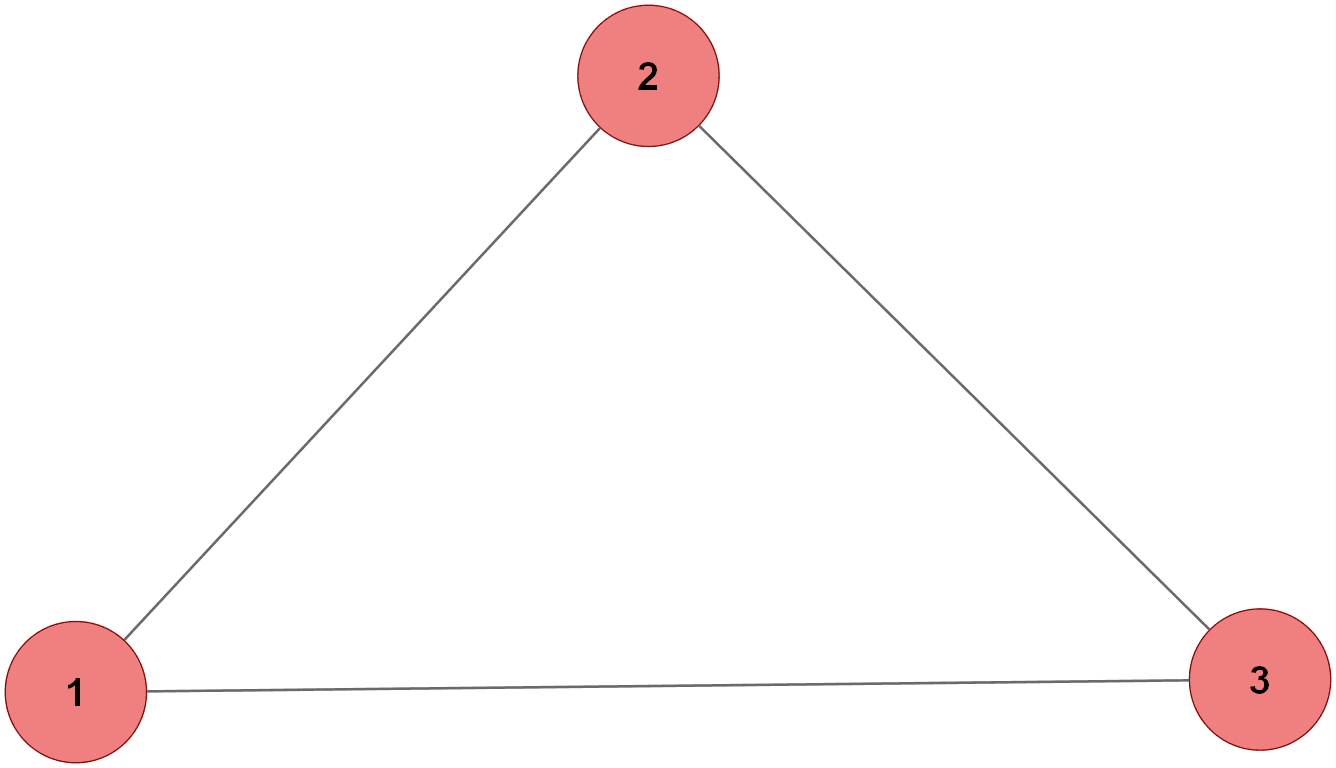
Question 9 — 3-regular Graph
Topologie du 3-regular Graph
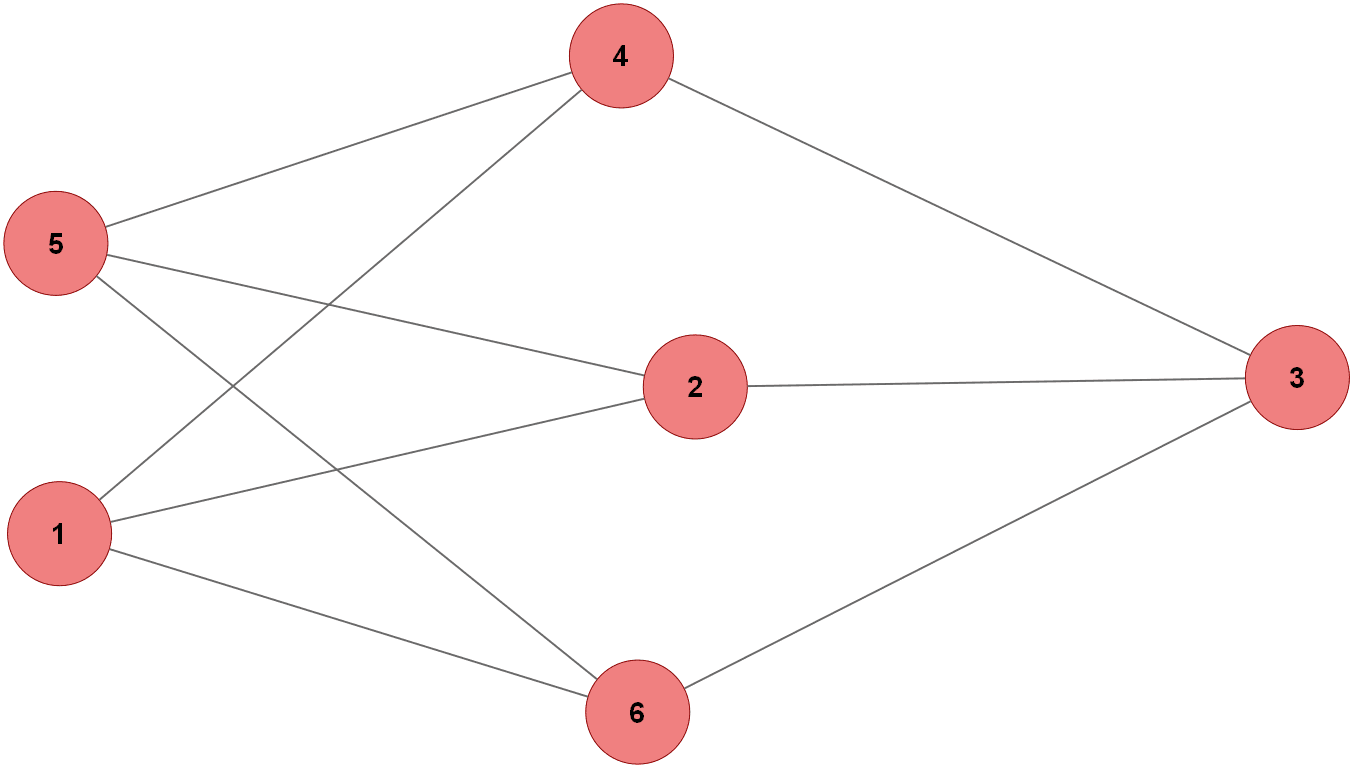
Le code crée un réseau 3-régulier de 6 nœuds en définissant des arêtes spécifiques entre eux. Pour chaque arête entre les nœuds i et j, une structure Communications est initialisée avec des canaux pour les jobs, les heartbeats et les réponses dans les deux directions. Deux routines Node sont lancées pour chaque paire i-j : une pour i vers j et une pour j vers i. Chaque Node active les modules d’envoi de jobs, de gestion des jobs reçus, de détection de pannes et de réponse aux heartbeats. Ainsi, chaque nœud communique avec trois autres nœuds via des canaux dédiés, formant un réseau 3-régulier où chaque nœud a exactement trois connexions.
package main
import (
"time"
"fmt"
)
type Communications struct {
Jobs_ij chan int
Jobs_ji chan int
Heartbeat_ij chan int
Heartbeat_ji chan int
HeartbeatReply_ij chan int
HeartbeatReply_ji chan int
}
func Node(id int, Interarrival_time int,
Jobs_Sent chan int, Jobs_Received chan int,
Heartbeat_Sent chan int, ACK_Received chan int,
Heartbeat_Received chan int, ACK_Sent chan int) {
go sending_job(id, Interarrival_time, Jobs_Sent)
go handling_jobs(id, Jobs_Received)
go failure_detector(id, Heartbeat_Sent, ACK_Received)
go answering_heartbeat(id, Heartbeat_Received, ACK_Sent)
}
func main() {
var listCommunications []Communications
// ---- Edges for the 3-regular 6-node graph ----
edges_i := []int{
1, 1, 1,
2, 2,
3, 3,
4,
5,
}
edges_j := []int{
2, 6, 4,
3, 5,
4, 6,
5,
6,
}
for k := range edges_i {
i := edges_i[k]
j := edges_j[k]
var C Communications
C.Jobs_ij = make(chan int, 5)
C.Jobs_ji = make(chan int, 5)
C.Heartbeat_ij = make(chan int, 5)
C.Heartbeat_ji = make(chan int, 5)
C.HeartbeatReply_ij = make(chan int, 5)
C.HeartbeatReply_ji = make(chan int, 5)
listCommunications = append(listCommunications, C)
// i → j
go Node(
i, 1,
C.Jobs_ij, C.Jobs_ji,
C.Heartbeat_ij, C.HeartbeatReply_ji,
C.Heartbeat_ji, C.HeartbeatReply_ij,
)
// j → i
go Node(
j, 1,
C.Jobs_ji, C.Jobs_ij,
C.Heartbeat_ji, C.HeartbeatReply_ij,
C.Heartbeat_ij, C.HeartbeatReply_ji,
)
}
fmt.Println("3-regular network of 6 nodes running...")
time.Sleep(10 * time.Second)
}Timeout:
secondes
Question 10 — Average version
On commence par créer la structure message. On doit simplement définir un nouveau type de message avg_list qui contiendra un snapshot des moyennes locales de chaque node. Ensuite, on modifie la structure Communications pour y inclure les canaux de JobMessage au lieu des canaux d'int. Le reste de l'implémentation suivra dans la suite du lab.
type JobMessage struct {
Type string // "job" ou "avg_list"
JobID int // id du job si Type == "job"
Sender int // id du node émetteur
AllAvgs []float64 // snapshot des moyennes (Type == "avg_list")
}
type Communications struct {
Jobs_ij chan JobMessage
Jobs_ji chan JobMessage
Heartbeat_ij chan int
Heartbeat_ji chan int
HeartbeatReply_ij chan int
HeartbeatReply_ji chan int
}On doit alors modifier les différentes routines pour qu'elles utilisent le nouveau type de message. Le failure detector doit maintenant publier des snapshots de la table des moyennes locales lorsqu'il reçoit un ACK. Le sending_job doit aussi être modifié pour qu'il puisse envoyer ces snapshots aux voisins. Enfin, le handling_jobs doit être mis à jour pour qu'il puisse traiter les messages de type avg_list et mettre à jour la table des moyennes locales en conséquence.
func failure_detector(id int, Heartbeat_Sent chan int, ACK_Received chan int, avgListChan chan<- []float64, allAverages *[]float64, muAvg *sync.Mutex) {
var j int = 1
var average_response_time float64 = 1.0
var i float64 = 1.0
// envoie premier heartbeat
start := time.Now()
Heartbeat_Sent <- j
for {
select {
case <-time.After(2 * time.Second):
// timeout -> pas d'ACK à temps
elapsed := float64(time.Since(start).Seconds())
fmt.Printf("node %d → timeout on heartbeat %d (est %.3f s, local avg %.3f s)\n",
id, j, elapsed, average_response_time)
return
case ack, ok := <-ACK_Received:
if !ok {
return
}
if ack != j {
fmt.Printf("node %d → received stale ACK %d (expect %d), ignoring\n", id, ack, j)
continue
}
// RTT pour ce heartbeat en secondes
elapsed := float64(time.Since(start).Seconds())
// mise à jour moyenne locale (exponential average simple via count i)
average_response_time = (average_response_time*i + elapsed) / (i + 1)
i++
// met à jour la vue locale (sa propre entrée)
muAvg.Lock()
if id >= 0 && id < len(*allAverages) {
(*allAverages)[id] = average_response_time
}
// préparer un snapshot (copie) de la table locale
snapshot := make([]float64, len(*allAverages))
copy(snapshot, *allAverages)
muAvg.Unlock()
// publier le snapshot NON BLOQUANT pour que sending_job l'envoie aux voisins
select {
case avgListChan <- snapshot:
// envoyé
default:
// buffer plein -> drop (on ne bloque pas)
}
// calculer moyenne globale à partir de la vue locale
muAvg.Lock()
sum := 0.0
cnt := 0
for idx, v := range *allAverages {
if idx == 0 {
continue
}
if v > 0 {
sum += v
cnt++
}
}
muAvg.Unlock()
globalAvg := 0.0
if cnt > 0 {
globalAvg = sum / float64(cnt)
}
fmt.Printf("node %d → ACK heartbeat %d (rtt %.3f s, local avg %.3f s, global avg %.3f s)\n",
id, j, elapsed, average_response_time, globalAvg)
// next heartbeat
j++
start = time.Now()
Heartbeat_Sent <- j
}
}
}
func answering_heartbeat(id int, Heartbeat_Received chan int, ACK_Sent chan int) {
for {
hb, ok := <-Heartbeat_Received
if !ok {
return
}
// simule une petite latence proportionnelle à id
time.Sleep(time.Duration(id) * time.Second)
ACK_Sent <- hb
fmt.Printf("node %d → ACK heartbeat %d\n", id, hb)
}
}
func sending_job(id int, interarrival_time int, Jobs_Sent chan JobMessage, avgListSource <-chan []float64) {
jobID := 1
for {
// envoyer job courant
Jobs_Sent <- JobMessage{Type: "job", JobID: jobID, Sender: id}
fmt.Printf("node %d → sent job %d\n", id, jobID)
jobID++
// si un snapshot est disponible, l'envoyer aux voisins
select {
case snapshot := <-avgListSource:
// envoyer la liste complète
Jobs_Sent <- JobMessage{Type: "avg_list", Sender: id, AllAvgs: snapshot}
fmt.Printf("node %d → sent avg_list (len=%d)\n", id, len(snapshot))
default:
// rien à envoyer pour les avgs cette ronde
}
time.Sleep(time.Duration(interarrival_time) * time.Second)
}
}
func handling_jobs(id int, Jobs_Received chan JobMessage, allAverages *[]float64, muAvg *sync.Mutex) {
for msg := range Jobs_Received {
switch msg.Type {
case "job":
fmt.Printf("node %d → received job %d from %d (processed)\n", id, msg.JobID, msg.Sender)
case "avg_list":
recv := msg.AllAvgs
// guarder la longueur minimale
muAvg.Lock()
if len(recv) > 0 {
for idx := 1; idx <= 6 && idx < len(*allAverages) && idx < len(recv); idx++ {
rv := recv[idx]
if rv > 0 {
local := (*allAverages)[idx]
if local > 0 {
(*allAverages)[idx] = (local + rv) / 2.0
} else {
(*allAverages)[idx] = rv
}
}
}
}
muAvg.Unlock()
fmt.Printf("node %d → received avg_list from %d and merged\n", id, msg.Sender)
default:
fmt.Printf("node %d → received unknown job type '%s'\n", id, msg.Type)
}
}
}
func NodeLab4(id int, Interarrival_time int,
Jobs_Sent chan JobMessage, Jobs_Received chan JobMessage,
Heartbeat_Sent chan int, ACK_Received chan int,
Heartbeat_Received chan int, ACK_Sent chan int) {
// vue locale des moyennes : indices 0..NNodes (on ignore 0)
localAverages := make([]float64, 6+1)
muAvg := &sync.Mutex{}
// canal local pour publier snapshots de la table locale (bidirectionnel côté créateur)
avgListChan := make(chan []float64, 5)
// Lancer sous-modules
go sending_job(id, Interarrival_time, Jobs_Sent, avgListChan) // lit avgListChan
go handling_jobs(id, Jobs_Received, &localAverages, muAvg)
go failure_detector(id, Heartbeat_Sent, ACK_Received, avgListChan, &localAverages, muAvg)
go answering_heartbeat(id, Heartbeat_Received, ACK_Sent)
}
func main() {
var listCommunications []CommunicationsQ10
out := ""
// edges for a 3-regular 6-node graph (same as before)
edges_i := []int{
1, 1, 1,
2, 2,
3, 3,
4,
5,
}
edges_j := []int{
2, 6, 4,
3, 5,
4, 6,
5,
6,
}
for k := range edges_i {
i := edges_i[k]
j := edges_j[k]
var C CommunicationsQ10
C.Jobs_ij = make(chan JobMessage, 10)
C.Jobs_ji = make(chan JobMessage, 10)
C.Heartbeat_ij = make(chan int, 10)
C.Heartbeat_ji = make(chan int, 10)
C.HeartbeatReply_ij = make(chan int, 10)
C.HeartbeatReply_ji = make(chan int, 10)
listCommunications = append(listCommunications, C)
// i -> j
go NodeLab4(
i, 2,
C.Jobs_ij, C.Jobs_ji,
C.Heartbeat_ij, C.HeartbeatReply_ji,
C.Heartbeat_ji, C.HeartbeatReply_ij,
&out,
count,
)
// j -> i
go NodeLab4(
j, 2,
C.Jobs_ji, C.Jobs_ij,
C.Heartbeat_ji, C.HeartbeatReply_ij,
C.Heartbeat_ij, C.HeartbeatReply_ji,
&out,
count,
)
}
fmt.Printf("Q10: 3-regular network of 6 nodes running (avg_list exchange)...\n")
// laisser tourner un peu pour accumuler logs
time.Sleep(12 * time.Second)
}
Timeout:
secondes